►Basic Introduction

Lets Learn Embedded Systems and Embedded Projects...
Saturday, December 10, 2011
keil C Programming Tutorial: Interfacing C programs to Assembler
►Function Parameters
C51 make use of registers and memory locations for passing parameters. By default C function pass up to three parameters in registers and further parameters are passed in fixed memory locations. You can disable parameter passing in register using NOREGPARMS keyword. Parameters are passed in fixed memory location if parameter passing in register is disabled or if there are too many parameters to fit in registers.
►Parameter passing in registers
C functions may pass parameter in registers and fixed memory locations. Following table gives an idea how registers are user for parameter passing.
C51 make use of registers and memory locations for passing parameters. By default C function pass up to three parameters in registers and further parameters are passed in fixed memory locations. You can disable parameter passing in register using NOREGPARMS keyword. Parameters are passed in fixed memory location if parameter passing in register is disabled or if there are too many parameters to fit in registers.
►Parameter passing in registers
C functions may pass parameter in registers and fixed memory locations. Following table gives an idea how registers are user for parameter passing.
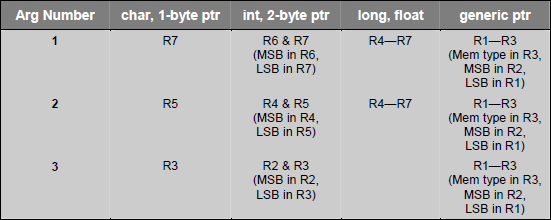
Following example explains a little more clearly the parameter passing technique:

Parameters passed to assembly routines in fixed memory lcoation use segments named
?function_name?BYTE : All except bit parameters are defined in this segment.
?function_name?BIT : Bit parameters are defined in this segment.
All parameters are assigned in this space even if they are passed using registers. Parameters are stored in the order in which they are declared in each respective segment.
The fixed memory locations used for parameters passing may be in internal data memory or external data memory depending upon the memory model used. The SMALL memory model is the most efficient and uses internal data memory for parameter segment. The COMPACT and LARGE models use external data memory for the parameter passing segments.
Function return values are always passed using CPU registers. The following table lists the possible return types and the registers used for each.
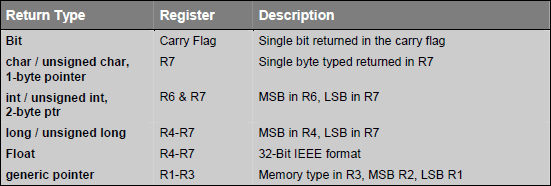
►Example
Following example shows how these segment and function decleration is done in assembler.
CODE:
;Assembly program example which is compatible
;and called from any C program
;lets say asm_test.asm is file name
name asm_test
;We are going to write a function
;add which can be used in c programs as
; unsigned long add(unsigned long, unsigned long);
; as we are passing arguments to function
;so function name is prefixed with '_' (underscore)
;code segment for function "add"
?PR?_add?asm_test segment code
;data segment for function "add"
?DT?_add?asm_test segment data
;let other function use this data space for passing variables
public ?_add?BYTE
;make function public or accessible to everyone
public _add
;define the data segment for function add
rseg ?DT?_add?asm_test
?_add?BYTE:
parm1: DS 4 ;First Parameter
parm2: ds 4 ;Second Parameter
;either you can use parm1 for reading passed value as shown below
;or directly use registers used to pass the value.
rseg ?PR?_add?asm_test
_add:
;reading first argument
mov parm1+3,r7
mov parm1+2,r6
mov parm1+1,r5
mov parm1,r4
;param2 is stored in fixed location given by param2
;now adding two variables
mov a,parm2+3
add a,parm1+3
;after addition of LSB, move it to r7(LSB return register for Long)
mov r7,a
mov a,parm2+2
addc a,parm1+2
;store second LSB
mov r6,a
mov a,parm2+1
addc a,parm1+1
;store second MSB
mov r5,a
mov a,parm2
addc a,parm1
;store MSB of result and return
;keil will automatically store it to
;varable reading the resturn value
mov r4,a
ret end
;and called from any C program
;lets say asm_test.asm is file name
name asm_test
;We are going to write a function
;add which can be used in c programs as
; unsigned long add(unsigned long, unsigned long);
; as we are passing arguments to function
;so function name is prefixed with '_' (underscore)
;code segment for function "add"
?PR?_add?asm_test segment code
;data segment for function "add"
?DT?_add?asm_test segment data
;let other function use this data space for passing variables
public ?_add?BYTE
;make function public or accessible to everyone
public _add
;define the data segment for function add
rseg ?DT?_add?asm_test
?_add?BYTE:
parm1: DS 4 ;First Parameter
parm2: ds 4 ;Second Parameter
;either you can use parm1 for reading passed value as shown below
;or directly use registers used to pass the value.
rseg ?PR?_add?asm_test
_add:
;reading first argument
mov parm1+3,r7
mov parm1+2,r6
mov parm1+1,r5
mov parm1,r4
;param2 is stored in fixed location given by param2
;now adding two variables
mov a,parm2+3
add a,parm1+3
;after addition of LSB, move it to r7(LSB return register for Long)
mov r7,a
mov a,parm2+2
addc a,parm1+2
;store second LSB
mov r6,a
mov a,parm2+1
addc a,parm1+1
;store second MSB
mov r5,a
mov a,parm2
addc a,parm1
;store MSB of result and return
;keil will automatically store it to
;varable reading the resturn value
mov r4,a
ret end
Now calling this above function from a C program is very simple. We make function call as normal function as shown below:
CODE:
extern unsigned long add(unsigned long, unsigned long);
void main(){
unsigned long a;
a = add(10,30);
//a will have 40 after execution
while(1);
}
void main(){
unsigned long a;
a = add(10,30);
//a will have 40 after execution
while(1);
}
keil C Programming Tutorial: C and Assembly together
►Interfacing C program to Assembler
You can easily interface your programs to routines written in 8051 Assembler. All you need to do is follow few programming rules, you can call assembly routines from C and vice-versa. Public variables declared in assembly modules are available to your C program.
There maybe several reasons to call an assembly routine like faster execution of program, accessing SFRs directly using assembly etc. In this part of tutorial we will discuss how to write assembly progarms that can be directly interfaced with C programs.
For any assembly routine to be called from C program, you must know how to pass parameters or arguements to fucntion and get return values from a function.
►Segment naming
C51 compiler generates objects for every program like program code, program data and constant data. These objects are stored in segments which are units of code or data memory. Segment naming is standard for C51 compiler, so every assembly program need to follow this convention.
Segment names include module_name which is the name of the source file in which the object is declared. Each segment has a prefix that corresponds to memory type used for the segment. Prefix is enclosed in question marks (?). The following is the list of the standard segment name prefixes:
You can easily interface your programs to routines written in 8051 Assembler. All you need to do is follow few programming rules, you can call assembly routines from C and vice-versa. Public variables declared in assembly modules are available to your C program.
There maybe several reasons to call an assembly routine like faster execution of program, accessing SFRs directly using assembly etc. In this part of tutorial we will discuss how to write assembly progarms that can be directly interfaced with C programs.
For any assembly routine to be called from C program, you must know how to pass parameters or arguements to fucntion and get return values from a function.
►Segment naming
C51 compiler generates objects for every program like program code, program data and constant data. These objects are stored in segments which are units of code or data memory. Segment naming is standard for C51 compiler, so every assembly program need to follow this convention.
Segment names include module_name which is the name of the source file in which the object is declared. Each segment has a prefix that corresponds to memory type used for the segment. Prefix is enclosed in question marks (?). The following is the list of the standard segment name prefixes:

►Data Objects:
Data objects are the variables and constants you declare in your C programs. The C51 compiler generates a saperate segment for each memory type for which variable is declared. The following table lists the segment names generated for different variable data objects.

►Program Objects:
Program onjects includes code generated for C programs functions by C51 compiler. Each function in a source module is assigned a separate code segment using the ?PR?function_name?module_name naming convention. For example, for a function name send_char in file name uart.c will have a segment name of ?PR?SEND_CHAR?UART.
C51 compiler creates saperate segments for local variables that are declared within the body of a function. Segment naming conventions for different memory models are given in following tables:



Function names are modified slightly depending on type of function (functions without arguments, functions with arguments and reentrant functions). Following tables explains the segment names:

In next section we will learn regarding defining functions which can be called from any C function and how a C function can be called from assembly.
keil C Programming Tutorial: Writing simple C program in Keil
►Basic of a C program
As we already discussed, Keil C is not much different from a normal C program. If you know assembly, writing a C program is not a problem, only thing you have to keep in mind is forget your controller has general purpose registers, accumulators or whatever. But do not forget about Ports and other on chip peripherals and related registers to them.
In basic C, all programs have atleast one function which is entry point for your application that function is named as "main" function. Similarly in keil, we will have a main function, in which all your application specific work will be defined. Lets move further deep into the working of applications and programs.
When you run your C programs in your PC or computer, you run them as a child program or process to your Operating System so when you exit your programs (exits main function of program) you come back to operating system. Whereas in case of embedded C, you do not have any operating system running in there. So you have to make sure that your program or main file should never exit. This can be done with the help of simple while(1) or for(;;) loop as they are going to run infinitely. Following layout provides a skeleton of Basic C program.
CODE:
void main(){
//Your one time initialization code will come here
while(1){
//while 1 loop
//This loop will have all your application code
//which will run infinitely
}
}
//Your one time initialization code will come here
while(1){
//while 1 loop
//This loop will have all your application code
//which will run infinitely
}
}
When we are working on controller specific code, then we need to add header file for that controller. I am considering you have already gone through "Keil Microvision" tutorial. After project is created, add the C file to project. Now first thing you have to do is adding the header file. All you have to do is right click in editor window, it will show you correct header file for your project.
Figure below shows the windows context for adding header file to your c file.
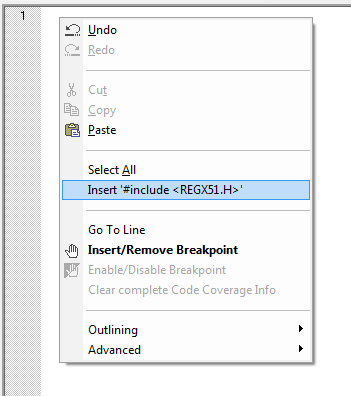
►Writing Hardware specific code
In harware specific code, we use hardware peripherals like ports, timers and uart etc. Do not forget to add header file for controller you are using, otherwise you will not be able to access registers related to peripherals.
Lets write a simple code to Blink LED on Port1, Pin1.
CODE:
#include <REGx51.h> //header file for 89C51
void main(){
//main function starts
unsigned int i;
//Initializing Port1 pin1
P1_1 = 0; //Make Pin1 o/p
while(1){
//Infinite loop main application
//comes here
for(i=0;i<1000;i++)
; //delay loop
P1_1 = ~P1_1;
//complement Port1.1
//this will blink LED connected on Port1.1
}
}
void main(){
//main function starts
unsigned int i;
//Initializing Port1 pin1
P1_1 = 0; //Make Pin1 o/p
while(1){
//Infinite loop main application
//comes here
for(i=0;i<1000;i++)
; //delay loop
P1_1 = ~P1_1;
//complement Port1.1
//this will blink LED connected on Port1.1
}
}
You can now try out more programs. "Practice makes a man perfect".
In next section of this tutorial, we will learn how to mix C and assembly codes.
keil C Programming Tutorial: Functions
►Functions in Keil C
Keil C compiler provides number of extensions for standarad C function declerations. These extensions allows you to:
- Specify a function as an interrupt procedure
- Choose the register bank used
- Select memory model
►Function Declaration:
[Return_type] Fucntion_name ( [Arguments] ) [Memory_model] [reentrant] [interrupt n] [using n]
Return_type: The type of value returned from the function. If return type of a function is not specified, int is assumed by default.
Function_name: Name of function.
Arguments: Arguments passed to function.
Options:
These are options that you can specify along with function declaration.
Memory_model: explicit memory model (Large, Compact, Small) for the function. Example:
CODE:
int add_number (int a, int b) Large
reentrant: To indicate if the function is reentrant or recursive. This option is explained later in the tutorial.
interrupt: Indicates that function is an interrupt service routine. This option is explained later in the tutorial.
using: Specify register bank to be used during function execution. We have three register banks in 8051 architecture. These register banks are specified using number 0 for Bank 0 to 3 for Bank 3 as shown in example
CODE:
void function_name () using 2{ //function uses Bank 2
//function code
}
//function code
}
►Interrupt Service Routines:
A function can be specified as an interrupt service routine using the keyword interrupt and interrupt number. The interrupt number indicates the interrupt for which the function is declared as service routine.
Following table describes the default interrupts:
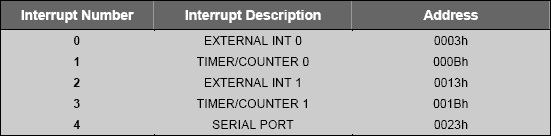
As 8051 vendors create new parts, more interrupts are added. Keil C51 compiler supports interrupt functions for 32 interrupts (0-31). Use the interrupt vector address in the following table to determine the interrupt number.
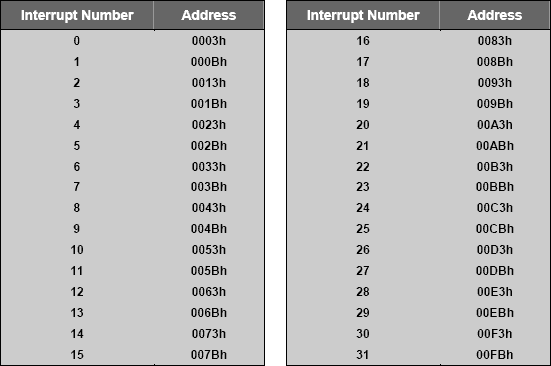
The interrupt function can be declared as follows:
CODE:
void isr_name (void) interrupt 2 {
// Interrupt routine code
}
// Interrupt routine code
}
Please make sure that interrupt service routines should not have any arguments or return type except void.
►Reentrant Functions:
In ANSI C we have recursive function, to meet the same requirement in embedded C, we have reentrant function. These functions can be called recursively and can be called simultaneously by two or more processes.
Now you might be thinking, why special definition for recursive functions?
Well you must know how these functions work when they are called recursively. when a function is running there is some runtime data associated with it, like local variables associated with it etc. when the same function called recursively or two process calls same function, CPU has to maintain the state of function along with its local variables.
Reentrant functions can be defined as follows:
CODE:
void function_name (int argument) reentrant {
//function code
}
//function code
}
Each reentrant function has reentrant stack associated with it, which is defined by startup.A51 file. Reentrant stack area is simulated internal or external memory depending upon the memory model used:
- Small model reentrant functions simulate reentrant stack in idata memory.
- Compant model reentrant functions simulate reentrant stack in pdata memory.
- Large model reentrant functions simulate reentrant stack in xdata memory.
►Real-time Function Tasks:
Keil or C51 provides support for real-time operating system (RTOS) RTX51 Full and RTX51 Tiny. Real-time function task are declared using _task_ and _priority_ keywords. The _task_ defines a function as real-time task. The _priority_ keyword specify the priority of task.
Fucntions are declared as follows:
CODE:
void func (void) _task_ Number _priority_ Priority {
//code
}
//code
}
where:
Number: is task ID from 0 to 255 for RTX51 Full and 0 to 15 for RTX51 Tiny.
Priority: is priority of task.
Real-time task functions must be declared with void return type and void argument list (say no arguments passed to task function).
keil C Programming Tutorial: Pointers
►Pointers in Keil C
Pointers in keil C is are similar to that of standard C and can perform all the operations that are available in standard C. In addition, keil C extends the operatability of pointers to match with the 8051 Controller architecture. Keil C provides two different types of pointers:
- Generic Pointers
- Memory-Specific Pointers
►Generic Pointers:
Generic Pointers are declared same as standard C Pointers as shown below:
CODE:
char *ptr; //Character Pointer
int *num; //Integer Pointer
int *num; //Integer Pointer
Generic pointers are always stored using three bytes. The first byte is the memory type, the second byte is the high-order byte of the offset, and the third byte is the low-order byte of the offset. Generic pointers maybe used to access any variable regardless of its location.
►Memory-Specific Pointers:
Memory specific pointers are defined along with memory type to which the pointer refers to, for example:
CODE:
char data *c;
//Pointer to character stored in Data memory
char xdata *c1;
//Pointer to character stored in External Data Memory.
char code *c2;
//Pointer to character stored in Code memory
//Pointer to character stored in Data memory
char xdata *c1;
//Pointer to character stored in External Data Memory.
char code *c2;
//Pointer to character stored in Code memory
As Memory-Specific pointers are defined with a memory type at compile time, so memory type byte as required for generic pointers is not needed. Memory-Specific pointers can be stored using 1 byte (for idata, data, bdata and pdata pointers) or 2 bytes (for code and xdata pointers).
The Code generated by keil C compiler for memory-specific pointer executes more quickly than the equivalent code generated for a generic pointer. This is because the memory area accessed by the pointer is known at the compile time rather at run-time. The compiler can use this information to optimize memory access. So If execution speed is your priority then it is recommended to use memory-specific pointers.
Generic pointers and Memory-Specific pointers can be declared with memory area in which they are to be stored. For example:
CODE:
//Generic Pointer
char * idata ptr; //character pointer stored in data memory
int * xdata ptr1; //Integer pointer stored in external data memory
//Memory Specific pointer
char idata * xdata ptr2; //Pointer to character stored in Internal Data memory
//and pointer is going to be stored in External data memory
int xdata * data ptr3; //Pointer to character stored in External Data memory
//and pointer is going to be stored in data memory
keil C Programming Tutorial (Part-1)
►Introduction
The use of C language to program microcontrollers is becoming too common. And most of the time its not easy to buld an application in assembly which instead you can make easily in C. So Its important that you know C language for microcontroller which is commonly known as Embedded C. As we are going to use Keil C51 Compiler, hence we also call it Keil C.
►Keywords:
Keil C51 compiler adds few more keywords to the scope C Language:
| _at_ | far | sbit |
| alien | idata | sfr |
| bdata | interrupt | sfr16 |
| bit | large | small |
| code | pdata | _task_ |
| compact | _priority_ | using |
| data | reentrant | xdata |
data/idata:
Description: The variable will be stored in internal data memory of controller.
example:
CODE:
unsigned char data x;
//or
unsigned char idata y;
//or
unsigned char idata y;
bdata:
Description: The variable will be stored in bit addressable memory of controller.
example:
CODE:
unsigned char bdata x;
//each bit of the variable x can be accessed as followsx ^ 1 = 1; //1st bit of variable x is set
x ^ 0 = 0; //0th bit of variable x is cleared
xdata:
Description: The variable will be stored in external RAM memory of controller.
example:
CODE:
unsigned char xdata x;
code:
Description: This keyword is used to store a constant variable in code memory. Lets say you have a big string which is not going to change anywhere in program. Wasting ram for such string will be foolish thing. So instead we will make use of the keyword "code" as shown in example below.
example:
CODE:
unsigned char code str="this is a constant string";
pdata:
Description: This keyword will store the variable in paged data memory. This keyword is used occasionally.
example:
CODE:
unsigned char pdata x;
_at_:
Description: This keyword is used to store a variable on a defined location in ram.
example:
CODE:
unsigned char idata x _at_ 0x30;
// variable x will be stored at location 0x30
// in internal data memory
// variable x will be stored at location 0x30
// in internal data memory
sbit:
Description: This keyword is used to define a special bit from SFR (special function register) memory.
example:
CODE:
sbit Port0_0 = 0x80;
// Special bit with name Port0_0 is defined at address 0x80
// Special bit with name Port0_0 is defined at address 0x80
sfr:
Description: sfr is used to define an 8-bit special function register from sfr memory.
example:
CODE:
sfr Port1 = 0x90;
// Special function register with name Port1 defined at addrress 0x90
// Special function register with name Port1 defined at addrress 0x90
sfr16:
Description: This keyword is used to define a two sequential 8-bit registers in SFR memory.
example:
CODE:
sfr16 DPTR = 0x82;
// 16-bit special function register starting at 0x82
// DPL at 0x82, DPH at 0x83
// 16-bit special function register starting at 0x82
// DPL at 0x82, DPH at 0x83
using:
Description: This keyword is used to define register bank for a function. User can specify register bank 0 to 3.
example:
CODE:
void function () using 2{
// code
}
// Funtion named "function" uses register bank 2 while executing its code
// code
}
// Funtion named "function" uses register bank 2 while executing its code
Interrupt:
Description: This keyword will tells the compiler that function described is an interrupt service routine. C51 compiler supports interrupt functions for 32 interrupts (0-31). Use the interrupt vector address in the following table to determine the interrupt number.
example:
CODE:
void External_Int0() interrupt 0{
//code
}
//code
}
►Memory Models:
There are three kind of memory models available for the user:
- Small: All variables in internal data memory.
- Compact: Variables in one page, maximum 256 variables (limited due to addressing scheme, memory accessed indirectly using r0 and r1 registers)
- large: All variables in external ram. variables are accessed using DPTR.
Depending on our hardware configuration we can specify the momory models as shown below:
CODE:
//For Small Memory model
#pragma small
//For Compact memory model
#pragma compact
//For large memory model
#pragma large
What is Instruction set??
An instruction set, or instruction set architecture (ISA), is the part of the computer architecture related to programming, including the native data types, instructions, registers, addressing modes, memory architecture, interrupt and exception handling, and external I/O. An ISA includes a specification of the set of opcodes (machine language), and the native commands implemented by a particular processor.
Instruction set architecture is distinguished from the microarchitecture, which is the set of processor design techniques used to implement the instruction set. Computers with different microarchitectures can share a common instruction set. For example, the Intel Pentium and the AMD Athlon implement nearly identical versions of the x86 instruction set, but have radically different internal designs.
Some virtual machines that support bytecode for Smalltalk, the Java virtual machine, and Microsoft's Common Language Runtime virtual machine as their ISA implement it by translating the bytecode for commonly used code paths into native machine code, and executing less-frequently-used code paths by interpretation; Transmeta implemented the x86 instruction set atop VLIW processors in the same fashion.
TIMI
This concept can be extended to unique ISAs like TIMI (Technology-Independent Machine Interface) present in the IBM System/38 and IBM AS/400. TIMI is an ISA that is implemented by low-level software translating TIMI code into "native" machine code, and functionally resembles what is now referred to as a virtual machine. It was designed to increase the longevity of the platform and applications written for it, allowing the entire platform to be moved to very different hardware without having to modify any software except that which translates TIMI into native machine code, and the code that implements services used by the resulting native code. This allowed IBM to move the AS/400 platform from an older CISC architecture to the newer POWER architecture without having to rewrite or recompile any parts of the OS or software associated with it other than the aforementioned low-level code.
Machine language
Machine language is built up from discrete statements or instructions. On the processing architecture, a given instruction may specify:
- Particular registers for arithmetic, addressing, or control functions
- Particular memory locations or offsets
- Particular addressing modes used to interpret the operands
More complex operations are built up by combining these simple instructions, which (in a von Neumann architecture) are executed sequentially, or as otherwise directed by control flow instructions.
Instruction types
Some operations available in most instruction sets include:
- Data handling and Memory operations
- set a register (a temporary "scratchpad" location in the CPU itself) to a fixed constant value
- move data from a memory location to a register, or vice versa. This is done to obtain the data to perform a computation on it later, or to store the result of a computation.
- read and write data from hardware devices
- Arithmetic and Logic
- add, subtract, multiply, or divide the values of two registers, placing the result in a register, possibly setting one or more condition codes in a status register
- perform bitwise operations, taking the conjunction and disjunction of corresponding bits in a pair of registers, or the negation of each bit in a register
- compare two values in registers (for example, to see if one is less, or if they are equal)
- Control flow
- branch to another location in the program and execute instructions there
- conditionally branch to another location if a certain condition holds
- indirectly branch to another location, while saving the location of the next instruction as a point to return to (a call)
Complex instructions
Some computers include "complex" instructions in their instruction set. A single "complex" instruction does something that may take many instructions on other computers. Such instructions are typified by instructions that take multiple steps, control multiple functional units, or otherwise appear on a larger scale than the bulk of simple instructions implemented by the given processor. Some examples of "complex" instructions include:
- saving many registers on the stack at once
- moving large blocks of memory
- complex and/or floating-point arithmetic (sine, cosine, square root, etc.)
- performing an atomic test-and-set instruction
- instructions that combine ALU with an operand from memory rather than a register
A complex instruction type that has become particularly popular recently is the SIMD or Single-Instruction Stream Multiple-Data Stream operation or vector instruction, an operation that performs the same arithmetic operation on multiple pieces of data at the same time. SIMD have the ability of manipulating large vectors and matrices in minimal time. SIMD instructions allow easy parallelization of algorithms commonly involved in sound, image, and video processing. Various SIMD implementations have been brought to market under trade names such as MMX, 3DNow! and AltiVec.
Parts of an instruction

One instruction may have several fields, which identify the logical operation to be done, and may also include source and destination addresses and constant values. This is the MIPS "Add" instruction which allows selection of source and destination registers and inclusion of a small constant.
On traditional architectures, an instruction includes an opcode specifying the operation to be performed, such as "add contents of memory to register", and zero or more operand specifiers, which may specify registers, memory locations, or literal data. The operand specifiers may have addressing modes determining their meaning or may be in fixed fields.
In very long instruction word (VLIW) architectures, which include many microcode architectures, multiple simultaneous opcodes and operands are specified in a single instruction.
Some exotic instruction sets do not have an opcode field (such as Transport Triggered Architectures (TTA) or the Forth virtual machine), only operand(s). Other unusual "0-operand" instruction sets lack any operand specifier fields, such as some stack machines including NOSC.
Instruction length
The size or length of an instruction varies widely, from as little as four bits in some microcontrollers to many hundreds of bits in some VLIW systems. Processors used in personal computers, mainframes, and supercomputers have instruction sizes between 8 and 64 bits(The longest possible instruction on x86 is 15 bytes, that is 120 bits). Within an instruction set, different instructions may have different lengths. In some architectures, notably most reduced instruction set computers (RISC), instructions are a fixed length, typically corresponding with that architecture's word size. In other architectures, instructions have variable length, typically integral multiples of a byte or a halfword.
Representation
The instructions constituting a program are rarely specified using their internal, numeric form; they may be specified by programmers using an assembly language or, more commonly, may be generated by compilers.
Design
The design of instruction sets is a complex issue. There were two stages in history for the microprocessor. The first was the CISC (Complex Instruction Set Computer) which had many different instructions. In the 1970s, however, places like IBM did research and found that many instructions in the set could be eliminated. The result was the RISC (Reduced Instruction Set Computer), an architecture which uses a smaller set of instructions. A simpler instruction set may offer the potential for higher speeds, reduced processor size, and reduced power consumption. However, a more complex set may optimize common operations, improve memory/cache efficiency, or simplify programming.
Some instruction set designers reserve one or more opcodes for some kind of system call or software interrupt For example, MOS Technology 6502 uses 00H, Zilog Z80 uses the eight codes C7,CF,D7,DF,E7,EF,F7,FFH while Motorola 68000 use codes in the range A000..AFFFH.
Fast virtual machines are much easier to implement if an instruction set meets the Popek and Goldberg virtualization requirements.
The NOP slide used in Immunity Aware Programming is much easier to implement if the "unprogrammed" state of the memory is interpreted as a NOP.
On systems with multiple processors, non-blocking synchronization algorithms are much easier to implement if the instruction set includes support for something like "fetch-and-increment" or "load linked/store conditional (LL/SC)" or "atomic compare and swap".
Instruction set implementation
Any given instruction set can be implemented in a variety of ways. All ways of implementing an instruction set give the same programming model, and they all are able to run the same binary executables. The various ways of implementing an instruction set give different tradeoffs between cost, performance, power consumption, size, etc.
When designing the microarchitecture of a processor, engineers use blocks of "hard-wired" electronic circuitry (often designed separately) such as adders, multiplexers, counters, registers, ALUs etc. Some kind of register transfer language is then often used to describe the decoding and sequencing of each instruction of an ISA using this physical microarchitecture. There are two basic ways to build a control unit to implement this description (although many designs use middle ways or compromises):
- Early computer designs and some of the simpler RISC computers "hard-wired" the complete instruction set decoding and sequencing (just like the rest of the microarchitecture).
- Other designs employ microcode routines and/or tables to do this—typically as on chip ROMs and/or PLAs (although separate RAMs have been used historically).
There are also some new CPU designs which compile the instruction set to a writable RAM or flash inside the CPU (such as the Rekursiv processor and the Imsys Cjip), or an FPGA (reconfigurable computing). The Western Digital MCP-1600 is an older example, using a dedicated, separate ROM for microcode.
An ISA can also be emulated in software by an interpreter. Naturally, due to the interpretation overhead, this is slower than directly running programs on the emulated hardware, unless the hardware running the emulator is an order of magnitude faster. Today, it is common practice for vendors of new ISAs or microarchitectures to make software emulators available to software developers before the hardware implementation is ready.
Often the details of the implementation have a strong influence on the particular instructions selected for the instruction set. For example, many implementations of the instruction pipeline only allow a single memory load or memory store per instruction, leading to a load-store architecture (RISC). For another example, some early ways of implementing the instruction pipeline led to a delay slot.
The demands of high-speed digital signal processing have pushed in the opposite direction—forcing instructions to be implemented in a particular way. For example, in order to perform digital filters fast enough, the MAC instruction in a typical digital signal processor (DSP) must be implemented using a kind of Harvard architecture that can fetch an instruction and two data words simultaneously, and it requires a single-cycle multiply–accumulate multiplier.
Code density
In early computers, program memory was expensive, so minimizing the size of a program to make sure it would fit in the limited memory was often central. Thus the combined size of all the instructions needed to perform a particular task, the code density, was an important characteristic of any instruction set. Computers with high code density also often had (and have still) complex instructions for procedure entry, parameterized returns, loops etc. (therefore retroactively named Complex Instruction Set Computers, CISC). However, more typical, or frequent, "CISC" instructions merely combine a basic ALU operation, such as "add", with the access of one or more operands in memory (using addressing modes such as direct, indirect, indexed etc.). Certain architectures may allow two or three operands (including the result) directly in memory or may be able to perform functions such as automatic pointer increment etc. Software-implemented instruction sets may have even more complex and powerful instructions.
Reduced instruction-set computers, RISC, were first widely implemented during a period of rapidly growing memory subsystems and sacrifice code density in order to simplify implementation circuitry and thereby try to increase performance via higher clock frequencies and more registers. RISC instructions typically perform only a single operation, such as an "add" of registers or a "load" from a memory location into a register; they also normally use a fixed instruction width, whereas a typical CISC instruction set has many instructions shorter than this fixed length. Fixed-width instructions are less complicated to handle than variable-width instructions for several reasons (not having to check whether an instruction straddles a cache line or virtual memory page boundary for instance), and are therefore somewhat easier to optimize for speed. However, as RISC computers normally require more and often longer instructions to implement a given task, they inherently make less optimal use of bus bandwidth and cache memories.
Minimal instruction set computers (MISC) are a form of stack machine, where there are few separate instructions (16-64), so that multiple instructions can be fit into a single machine word. These type of cores often take little silicon to implement, so they can be easily realized in an FPGA or in a multi-core form. Code density is similar to RISC; the increased instruction density is offset by requiring more of the primitive instructions to do a task.
There has been research into executable compression as a mechanism for improving code density. The mathematics of Kolmogorov complexity describes the challenges and limits of this.
Number of operands
Instruction sets may be categorized by the maximum number of operands explicitly specified in instructions.
(In the examples that follow, a, b, and c are (direct or calculated) addresses referring to memory cells, while reg1 and so on refer to machine registers.)
- 0-operand (zero-address machines), so called stack machines: All arithmetic operations take place using the top one or two positions on the stack; 1-operand push and pop instructions are used to access memory: push a, push b, add, pop c.
- 1-operand (one-address machines), so called accumulator machines, include early computers and many small microcontrollers: most instructions specify a single right operand (that is, constant, a register, or a memory location), with the implicit accumulator as the left operand (and the destination if there is one): load a, add b, store c. A related class is practical stack machines which often allow a single explicit operand in arithmetic instructions: push a, add b, pop c.
- 2-operand — many CISC and RISC machines fall under this category:
- CISC — often load a,reg1; add reg1,b; store reg1,c on machines that are limited to one memory operand per instruction; this may be load and store at the same location
- CISC — move a->c; add c+=b.
- RISC — Requiring explicit memory loads, the instructions would be: load a,reg1; load b,reg2; add reg1,reg2; store reg2,c
- 3-operand, allowing better reuse of data:.
- CISC — It becomes either a single instruction: add a,b,c, or more typically: move a,reg1; add reg1,b,c as most machines are limited to two memory operands.
- RISC — arithmetic instructions use registers only, so explicit 2-operand load/store instructions are needed: load a,reg1; load b,reg2; add reg1+reg2->reg3; store reg3,c; unlike 2-operand or 1-operand, this leaves all three values a, b, and c in registers available for further reuse.
- more operands—some CISC machines permit a variety of addressing modes that allow more than 3 operands (registers or memory accesses), such as the VAX "POLY" polynomial evaluation instruction.
Due to the large number of bits needed to encode the three registers of a 3-operand instruction, RISC processors using 16-bit instructions are invariably 2-operand machines, such as the Atmel AVR, the TI MSP430, and some versions of the ARM Thumb. RISC processors using 32-bit instructions are usually 3-operand machines, such as processors implementing the Power Architecture, the SPARC architecture, the MIPS architecture, the ARM architecture, and the AVR32 architecture.
Each instruction specifies some number of operands (registers, memory locations, or immediate values) explicitly. Some instructions give one or both operands implicitly, such as by being stored on top of the stack or in an implicit register. When some of the operands are given implicitly, the number of specified operands in an instruction is smaller than the arity of the operation. When a "destination operand" explicitly specifies the destination, the number of operand specifiers in an instruction is larger than the arity of the operation. Some instruction sets have different numbers of operands for different instructions.
List of ISAs
This list is far from comprehensive as old architectures are developed and new ones invented. There are many commercially available microprocessors and microcontrollers implementing ISAs. Customized ISAs are also quite common in some applications, e.g. ASIC, FPGA, and reconfigurable computing.
- List of instruction sets
ISAs implemented in hardware
- 4004, 4040
- 6800, 6502, 6809, 68HC11, 68HC08, etc.
- 8008, 8080, 8085, Z80, Z180, eZ80, etc.
- 8048, 8051, etc.
- Z8, eZ8, etc.
- Alpha
- ARM
- Burroughs large systems instruction sets
- Burroughs B5000 series
- Burroughs B6000/B7000 series
- Burroughs B8500
- eSi-RISC
- IA-64 (Itanium)
- Mico32
- MIPS
- Motorola 68k
- PA-RISC
- IBM 700/7000 lines
- IBM 701
- IBM 702
- IBM 704
- IBM 7010
- IBM 7030
- IBM 7040/7044
- IBM 7070/7072/7074
- IBM 705/7080
- IBM 709/7090/7094
- System/360 and upwards compatible successors
- System/370
- System/390
- z/Architecture
- Power Architecture
- POWER
- PowerPC
- PDP-11
- SPARC
- SuperH
- TriCore™
- Transputer
- UNIVAC 1100/2200 series
- VAX
- x86
- IA-32 (32-bit x86, first implemented in the Intel 80386)
- x86-64 (64-bit superset of IA-32, first implemented in the AMD Opteron)
- EISC (AE32K)
ISAs commonly implemented in software with hardware incarnations
- p-Code (UCSD p-System Version III on Western Digital Pascal MicroEngine)
- Java virtual machine (ARM Jazelle, picoJava, JOP)
- FORTH
- MMIX, a teaching machine used in Donald Knuth's The Art of Computer Programming
ISAs only implemented in software
- Common Intermediate Language (CIL) - The assembly language and instruction set developed for the Common Language Infrastructure (CLI), the standard that is the foundation of the Common Language Runtime (CLR) in the .NET Framework and the open-source implementation Mono.
ISAs never implemented in hardware
- ALGOL object code
- SECD machine, a virtual machine used for some functional programming languages.
- Z-machine, a virtual machine originated by Infocom and used for text adventure games, and its successor Glulx
Subscribe to:
Posts (Atom)